In a previous blog post, I detailed the most prevalent difficulties I came across when working to create my corpus. These difficulties, culminating with the act of having to manually collect around 1,400 comments, resulted in me taking a number of unintentional shortcuts that hindered my data analysis. Luckily, during the Q&A period of my project presentation, a number of my fellow students were able to bring to light a couple of problems resulting from these shortcuts which I have since begun to try and rectify.
For my data analysis, I chose to use Voyant Tools both because I found it easy to use and because it ran pretty well on my six-years-old Mac Mini (its on its last legs, unfortunately). I like Voyant Tools because it has a large number of help documents that provide insight into each and every individual tool on the platform. The platform’s interface itself is also very clean and easy to use and understand. I had no problem creating new stop words, adjusting the parameters for my preferred tools’ analysis, and swapping out tools on a whim. The platform occasionally crashed… but honestly that could just be an issue with my computer.
When I made my first attempts at text analysis, I used a single corpus made up of about 1,400 essentially unorganized comments taken from Douglas Coupland’s Instagram account. My hope was that this corpus would grant me a bit of insight into who Coupland’s commenters were; or, what kind of person is drawn to Coupland’s work.
Using this technique, I was able to pick up some, I would say, minor details. Using Cirrus, I was able to see a high-level view of the most used words in the comments. I found an interesting amount of positive language; love was used far more often than hate, like more often than dislike, yes more often than no, true more often than false, good more often than bad. Also, based on this wordcloud, people are clearly trying to get Coupland’s attention… his @ and his familiar name “Doug” appear with a surprising amount of frequency… the marker of an account that sees a lot of interaction from real world friends… or of an an account that has a large amount of folk stuck in a parasocial relationship.

Cirrus is a wordcloud view of the most frequently occuring words in the corpus or document.
There are, of course, a handful of issues one that I picked up on (and that was emphasized by my peers during the Q&A period of my presentation) is that folk tend to not communicate in a standardized way when writing online. I discussed this problem in my blog post on Topic Modeling; but, essentially the problem is in a handful of words: People say “not good” a lot and that’s… well, it’s not good.
My hope was that, using topic modeling (available through Voyant Tool’s Topics tool), I’d be able to perform a rudimentary kind of layman’s Sentiment Analysis (also discussed in the aforementioned blog). Using my original corpus, this proved to be… sort of doable, but with extremely mixed results. Running this procedure a couple of times, I noticed a couple of interesting topics: COVID anxiety / fear (which was in turn a source of many “negative” comments) and love for Coupland and the desire to see more of his work and, in particular, a new book. But there were a multitude of other topics that, at best, appeared to be random.
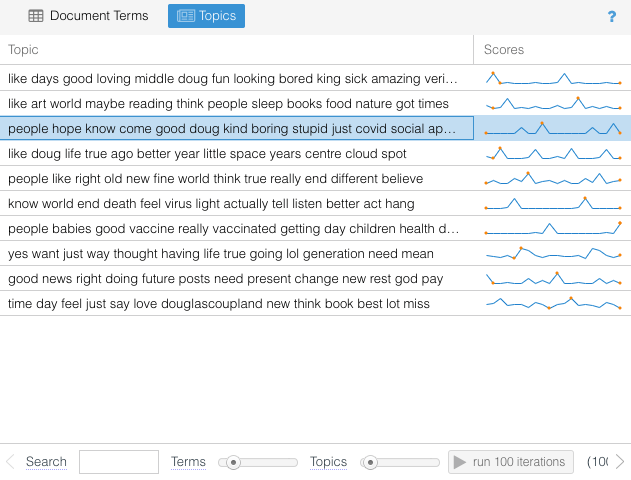
Topics performs topic modeling on the corpus or document.
During the Q&A period, another peer of mine recommended that I look at a handful of Slogans with a high-volume of comments, create unique files of comments for those Slogans, and then use those individual files for my text analysis… I discussed some of the reasons why I originally did not take this approach in a previous blog post, but ultimately, my peer was right, and the benefits of this approach outweighed the added annoyances that came with collecting the data. The resulting materials from Voyant Tools proved to be much more readable when I fed it data in this format, uploading TXT files collecting comments from six Slogans:
- WILL YOU WEAR A MASK TO PROTECT ANTIVAXXERS?
- I AM NOT ALLOWED TO VISIT MY MOTHER ANYMORE AND IT IS BREAKING MY HEART.
- MONEY’S ALMOST OVER. WHAT REPLACES IT?
- WORLD WAR THREE IS NEXT
- WHAT IF IT’S FINALLY ENDING?
- I LOVE THE PEOPLE IN MY LIFE
The resulting output included much more usable results; or at least, results which I could use to tell an interesting story.
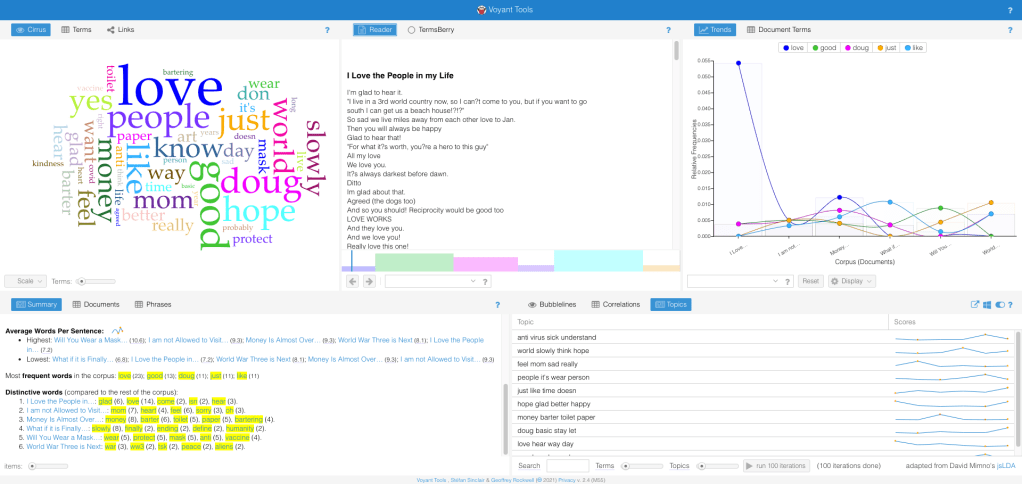
It’s this material that I have discussed in my final project, found: here.

One thought on “Data Collection, Text Analysis, and the Benefits of Peer Review Pt. 2”