While I have had a WordPress blog for a while, I have only very recently enhanced and updated it. I was able to do much of this work for a wonderful course I took last year (Spring 2021) called CCTP-850 Digital Presence & Strategic Persuasion. This course was aimed at students who sought to transform their digital presence into one that resembled that of a working professional. I believe I succeeded in meeting that course’s goals, but there were, of course, some difficulties:
- During the course, I attempted to combine both a working professional’s website with that of an academic’s… I think I succeeded in this? It’s a little tough to say because some elements of those two cultures simply do not mix well.
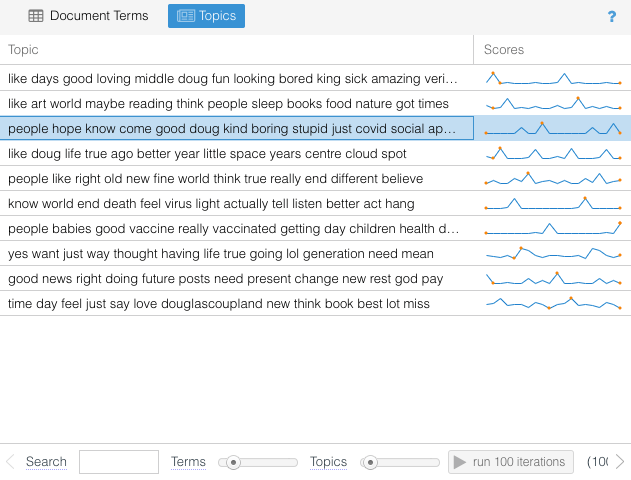
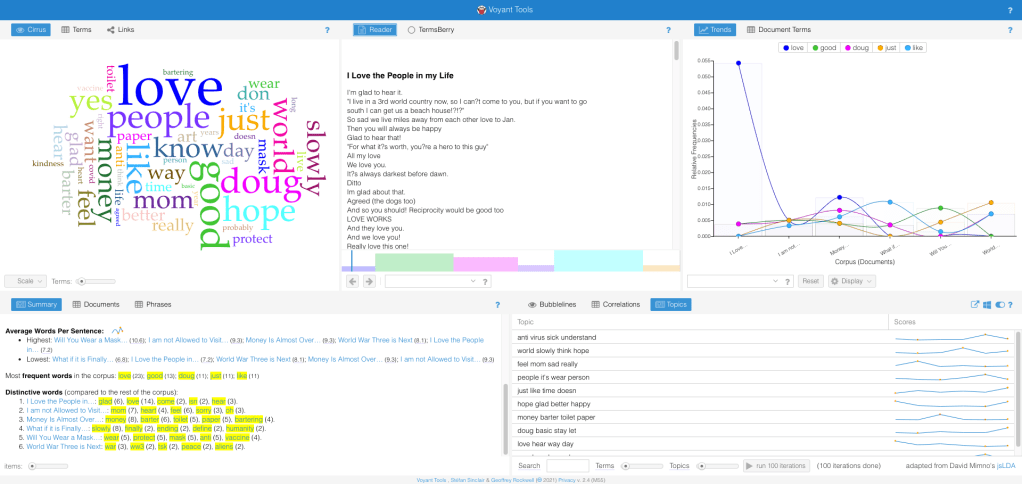
- My WordPress blog has some limitations… one of which was I couldn’t really create a nice looking timeline. Our instructor showed us numerous clean, professional looking timelines during the course that she recommended as tools for creating interesting looking résumés on our webpages. My WordPress blog’s inherent restrictions precluded me from utilizing them. Sad!
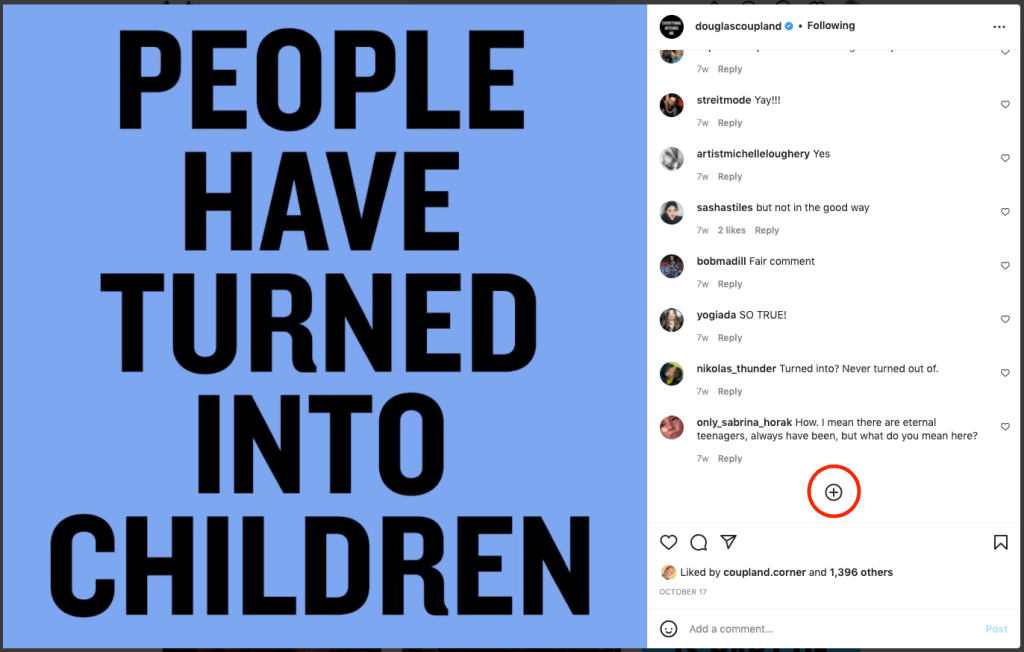
I really wanted to make a timeline. But my blog, being a WordPress dot com blog, is not compatible with plugins unless I spend a large amount of money. I’ve continued to struggle with WordPress in other areas as well… one thing I had hoped to do (and admittedly, this may be a problem with Instagram, another application that has given me grief over the years) is embed posts directly into webpages, when I try, this happens:
You can’t see anything! You have to actually follow the gigantic, space-hogging link to Instagram and view the post on the account owner’s page. WordPress includes one block—which I, incredibly, actually have access to—that will allow you to actually view posts on your page… but it only works with your account, and it appears to only show most recent posts, not a personalized selection.
During this semester’s (Fall 2021) ENGL-726-01 course, Digital Approaches to Literature… I was determined to get a win. When the course professor showed us Knight Lab’s Timeline JS I knew that I had to incorporate it into my final project. So I worked to do so, and created a timeline that you can view by following this link.
Yeah, you have to follow the link. Once again, I was sad to discover that my WordPress blog was not compatible with a timeline… according to Knight Lab, in order to make the timeline work on your blog’s page you need—you guessed it—a plugin. So I’ve done some research and have actually discovered that there is a way around this issue that, at least, at a first glance, appears to be relatively cheap. You can actually convert your WordPress dot com blog into a WordPress dot org blog… and, a WordPress dot org blog will actually allow you to use plugins without having to spend a whole lot of money. The process is a little complex, but I found numerous blogs—such as this one—that can assist with one such as myself who might like to do this one day.
Despite being unable to embed my Timeline JS directly into my WordPress blog… I’m keeping it. I’ve wanted to make a timeline for so long that I am already way too attached to it to even consider giving it up. And how could I not be? Knight Lab’s Timeline JS tool is incredibly easy to use and produces such a high-quality visualization.
I found that Knight Lab’s 4 step guide to making a Timeline JS was comprehensive and easy to follow… I did not even need to watch the brief tutorial video they made. The only issue I ran into was that I had not realized that its software could not read text edited using Google Spreadsheet’s text editor. This proved to be a simple problem to overcome, however, and I was able to use some of the HTML language we learned earlier in the course to add links and some color to my timeline. When searching for pleasing colors, I found a website called HTML Color Codes that proved to be invaluable help, it made it really easy to find appropriate HTML color codes for any color that I was seeking.
So while I do not have a high-quality timeline embedded directly in one of my project’s pages, you will still be able to find one linked in my project’s Table of Contents… My hope is that the linking back and forth between the Timeline JS and my final project is intuitive and unobtrusive.