Abstract
What are Emoji? Funny little images? A New Language? Or something else entirely? This paper will explore the topic of Emoji while attempting to take into account all facets of the characters’ unique identity. As such, this paper will address both the visual and encoding history of Emoji paying special attention to what encoding is and why it is important. It ends with a brief discussion pertaining to potential ambiguities inherent to the form and how those ambiguities are intrinsically tied to Emoji despite best intentions to minimize them. this will hopefully encourage the reader to be informed and understand what it is they are doing when they select an Emoji to electronically send out into the world.
So, what are Emoji?
You
Emoji are, according to WIRED writer Arielle Pardes (2018): “[L]ike a primitive language… the first language born into the digital world, designed to add nuance to otherwise flat text.” The projections of these abstract emotive characters—such as 💩—in digital environments have been widely adapted into worldwide digital text since a small selection of characters debuted on Japanese company SoftBank’s mobile phones in 1997 (Oliveria, 2021). The original black and white character set, seen in the image below, reveal perhaps Emoji’s most unique characteristic: They are encoded abstract characters—That is, according to the Unicode Consortium: “A unit of information used for the organization, control, or representation of textual data”—not, strictly speaking, graphics. Emoji are designed to be incorporated fluidly within digital text.

When considering a modern Emoji like 💩’s functioning, this intrinsic characteristic of the abstract character is made possible due to how it is encoded. Pardes (2018) states in the “Wired Guide to Emoji” that: “Since computers fundamentally work with numbers, every letter or character [someone] types is ‘encoded’ or represented with a numerical code.” This means that encoded abstract characters are those which are “mapped” to a code point and “abstract byte-code definition” or character identity, established by its character name and representative glyph image on a code chart. A code point is, according to the Unicode Consortium: A value, or position, for a character, in any coded character set. All the letters—and Emoji—you see on the screen in front of you are encoded characters following the Unicode Standard.
While reading this essay, you may have noticed several definitions provided by the Unicode Consortium, that is because the Unicode Consortium is the information technology standard for the consistent encoding, representation, and handling of digital text (which now includes Emoji). The Unicode Standard is defined by the Unicode Consortium as: “The standard for digital representation of the characters used in writing all of the world’s languages… providing a uniform means for storing, searching, and interchanging text in any language… [and] is the foundation for processing text on the [Web].” So how does this all work? Take the letter “A,” A is the interpreted projection of the Unicode code point U+0041, Unicode character name: “Latin Capital letter A.” 💩 is the interpreted projection of Unicode code point U+1F4A9, Unicode character name: “Pile of Poo.”
These Unicode code points are additionally mapped to byte sequences interpretable by computing systems, i.e. E-information; in Unicode Transformation Format — 8-bit (UTF-8), the most widely-used encoding scheme on the contemporary Web, the byte sequences are between one to four bytes in length. The variability in byte sequence length is advantageous because it allows commonly-used characters or glyphs to be mapped to single bytes—saving computer memory and reducing load speeds—while simultaneously leaving space for any-known character or glyph to be mapped to up to four bytes if need be. For example, A, or, Unicode Code Point U+0041 is mapped to the byte “01000001,” where each digit represents one piece of E-information—that is, one “bit”—interpretable by computing systems. 💩, or, Unicode Code Point U+1F4A9 is mapped to four bytes, “11110000 : 10011111 : 10010010 : 10101001.” In Unicode, all Emoji are mapped to four bytes.
Unicode code points such as U+0041 and U+1F4A9 go through two layers of interpretation within our computational devices.
- They are decoded by the Unicode-aware text software layer in whatever program one is using (in this instance, more likely than not, your Web browser), which matches the one through 4 byte strings mapped to the various Unicode code points to corresponding “language family” software installed on our computational devices (Irvine 2020, 10-11).
- Other layers of software match the decoded Unicode code point (and thus, its abstract Unicode character identity) with its graphical, pixel-shaped “font style” representation (Ibid 2020, 11).
Unicode code points must go through both layers of interpretation before computational devices are able to project the characters into pixels on our screens (Ibid 2020, 11).
So Emoji are interpreted projections of four bytes mapped to Unicode code points?
You
Emoji certainly can often contemporaneously be partially defined as such! But that definition is simplistic and does not provide the reader with the full story.
Emoji and Unicode, after all, were not designed simultaneously; nor was one designed with the other in mind. Emojis’ incorporation into Unicode was a near-guaranteed eventuality due to its designers three main goals, which were to create character encoding that was:
- Uniform (fixed-width codes for efficient access), and
- Unique (bit sequence has only one interpretation into character codes), and
- Universal (addressing the needs of world languages)
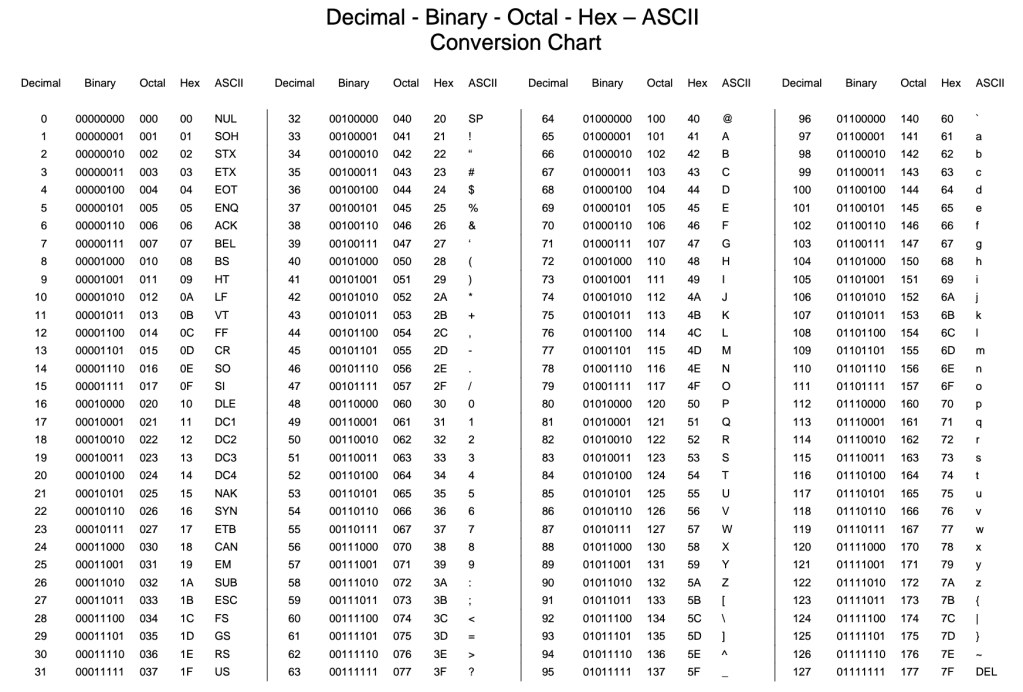
Prior to the design of the Unicode Standard, there were several decades of independent encoding schemes for abstract characters (Irvine 2020, 9). The multitude of independent encoding schemes were born out of necessity—after all, people had to figure out how to encode their languages’ characters and glyphs, their abstract “data,” or, “D-information” onto “electronic,” or, “E-information,” that is, physical, quantifiable patterns of electricity that are interpretable by computer systems—bits (Irvine 2022a, 5). Bits are the smallest unit of computable E-information; and, importantly, bits are physical, each bit takes up an amount of space on a computational device’s available storage or “memory.” As such, it was advantageous for designers to develop rules—encoding schemes, like UTF-8—that mapped characters and glyphs, or “D-information” onto as few bits as computationally possible (Zentgraf 2015). One early encoding scheme, American Standard Code for Information Interchange, ASCII, mapped 128 characters onto 128 defined 7-bit forms which is shown in the image of the ASCII Conversion Chart below (Ibid 2015). This encoding scheme worked for some—but not all—Latin languages and proved useful for Americans. Europeans looked at ASCII, noticed that an entire bit on each byte was always set to 0 in the scheme—seen in the first digit of each byte in the below ASCII Conversion Chart—and used that empty bit to add an additional 128 characters to the standard ASCII table… but even 256 available bytes falls far short of what would be needed to encode all of the world’s languages past, present, and future (ibid 2015). So, the world worked independently to create encoding schemes that utilized the common computer’s eight bits to the byte for language encoding, resulting in many language-specific encoding schemes, none of which were compatible with each other (Ibid 2015).
The Unicode Standard was initiated in early 1989 by an informal interdisciplinary working group of linguists, engineers, managers, and information professionals from companies and institutions requiring international information systems, developing into a consortium of major computer companies that formally affiliated as Unicode Inc., or, the Unicode Consortium. The Unicode Standard is the current international encoding standard. Unicode is the “glue” for representing all written characters of any language—past, present, and future— by specifying a standard code range for every language family, and code points and character descriptions for each character and glyph in each language (Irvine 2020, 9). The Unicode Standard is far more efficient and flexible than previous encoding standards, allowing folks to not have to sift through dozens of encoding standards when trying to project text from incompatible documents (Hu 2018). However, the Unicode Standard is not without its disadvantages, it is still fairly Western-centric, and Western characters and glyphs tend to be encoded onto smaller byte strings (in fact, the first 128 code points of Unicode are identical to the ASCII encoding table); additionally, the Unicode Standard can be slow to respond to new and changing encoding needs (Hu, 2018).
Case in point: Emoji!
Emoji were adopted into the Unicode Standard over a decade after the first Emoji appeared on Japanese mobile phones. During that decade, all Emoji—at the time, typically found on mobile devices—were tied a carrier and the computational devices that the carrier manufactured. This means that, the 176 Emoji below—created in 1999 by Japanese artist Shigetaka Kurita for “i-mode,” an early mobile Web platform from Japan’s main mobile carrier, DOCOMO—would more than likely not have been compatible with SoftBank mobile devices as both carriers likely used different encoding schemes for their respective Emoji (Pardes 2018). In other words, if a SoftBank device received a series of bytes from a DOCOMO device that meant to map to a DOCOMO Emoji’s code point, the SoftBank device would be unable to project the intended image; instead, the SoftBank device would likely project a placeholder character (something like □) meant to represent that while a character is present, the device does not have the encoding scheme required to project it as intended. Essentially, Emoji had the same encoding problem that the world’s languages had!

So, with a decade between the invention of Emoji and the adoption of Emoji into Unicode, what were Emoji lovers and want-to-havers to do? Many folk utilized emoticons, which were representations of facial expressions using combinations of existing Unicode (or other encoding scheme) characters. The Unicode Consortium has its own definition for emoticons, stating: “[Emoticons are a] symbol added to text to express emotional affect or reaction—for example, sadness, happiness, joking intent, sarcasm, and so forth. Emoticons are often expressed by a conventional kind of ‘ASCII art,’ using sequences of punctuation and other symbols to portray likenesses of facial expressions. In Western contexts these are often turned sideways, as : – ) to express a happy face.” The term “ASCII art” is informative because it shows that the concept of emoticons is old; in fact, these combinations of various encoding scheme’s characters were used throughout chat rooms since the early 1990s, representing an important part of early “netspeak” and highlighting a fascinating semiotic solution to a core encoding scheme design problem (Pardes 2018).
I thought you were going to tell me what Emoji are?
You
I am! But, in order to full understand what Emoji are it is important to understand how an applied semiotic principles underlies our digital information design (that is, the technique for encoding D-information onto E-information) (Irvine 2022a, 6). Emoticons function well as symbols to express emotional affect or reaction because encoding—even pre-Unicode—was relatively consistent in terms of how specific characters were encoded. A Latin Capital letter A will always kind of look like a capital A; A can be bold, A can be italicized, A, can be underlined, or in a new font entirely and it will (almost) always be a discernible projection of the same encoded character due to what can be called the token/type distinction. All the encoded characters that can be projected onto a computer screen are represented semiotic signs and symbols. In Peircean semiotics, the relationship between:
- “Individual, perceptible physical instances, in a medium at a single place and time, and
- The general patterns, forms, or types which can be given representation or expression an unlimited number of times in other physical media, and be interpreted with many kinds of meaning in different places and times and in different physical media”
IS the relationship between the token and the type (Irvine 2022b, 10). In simpler terms: tokens are the time and place and medium-specific instance of a symbolic form; types are the invariant patterns that hold over unlimited instances of a token (Ibid, 10).
Take the previous sentence, it contains many tokenizations of Unicode code points and character identities, but we’ll focus on two, “ : “ – Unicode code point U+003A, Unicode character name “Colon;” and “ ) “ – Unicode code point U+0029, Unicode character name “Right Parenthesis.” In the aforementioned sentence, those instances of the respective symbolic forms—those tokens—are recognized as grammatical symbols which help to define how the sentence should be read. We know this, because those symbolic forms are adhering to a meaningful pattern—an invariant combinatorial structure of symbols—that are recognizable by you, the—presumably English speaking—reader (Ibid 2022, 11-12). Now, let’s re-tokenize those specific aforementioned symbols like so: : )
Those symbols now adhere to a new meaningful pattern; the two new tokenizations of “ : “ – Unicode code point U+003A, Unicode character name “Colon;” and “ ) “ – Unicode code point U+0029, Unicode character name “Right Parenthesis” are no longer recognized as grammatical symbols, rather, they are recognized emoticons, or, combinatorial symbols added to text for emotional affect… a “happy face.” These symbols are not any different from the symbols used to define how a sentence is read. The symbols are re-tokenizations of the same two invariant types: Unicode code points, or, two separate strings of bytes with the abstract characters “ : “ and “ ) “ encoded onto each respectively. This is a semiotic solution to the encoding constraints of early encoding standards. Until Unicode, most encoding standards solely worked with between 128 and 256 bytes each of which could be used to encode a single character. By re-tokenizing available types of encoded characters into new meaningful patterns, people were able to many kinds of meaning with limited character sets.
So Emoji… are tokens?… are types?
You
YES, Emoji, as we see them, are “tokens,” individual, perceptible physical instances of “types” of (often Unicode) code points.
In 2007, a software internationalization team at Google petitioned the Unicode Consortium to have Emoji be incorporated into the Unicode Standard; other software teams from other companies joined over the next couple of years and soon, they submitted an official proposal to encode 625 characters (Pardes 2018). The proposal was accepted in 2010, and the Unicode Consortium decided to encode the selected 625 Emoji, “because of their use as characters for text-messaging in a number of Japanese manufacturers’ corporate [encoding standards],” meaning: Emoji are popular, it would be good if they could enjoy the same encoding standards as other languages’ characters and glyphs (Pardes 2018). This development gave Emoji common code points—Unicode code points—that could be interpreted and projected by the vast majority of the world’s computational devices (provided said devices have layers of software able to match the decoded Unicode code point with a pictograph representation).
The Unicode Consortium define Emoji as:
- The Japanese word for “pictograph,” coming from the Japanese 絵 (e ≅ picture) + 文字 (moji ≅ written character).
- Certain pictographic and other symbols encoded in the Unicode Standard that are commonly given a colorful or playful presentation when [projected] on devices. Many of the Emoji in Unicode were originally encoded for compatibility with Japanese telephone symbol sets.
- Colorful or playful symbols which are not encoded as characters but which are widely implemented as graphics.
While Unicode encodes Emoji onto Unicode code points and provide them with a character identity, Unicode does not determine the look of Emoji when projected onto a device. The pictographic representation of emoji comes from a software layer that is able to match decoded Unicode code points to the appropriate mapped image. This means that Apple, Google, Microsoft, and other companies are all creating their own tokenizations of the same types of code points. Say, you were selecting an Emoji to send someone like someone in the image below:
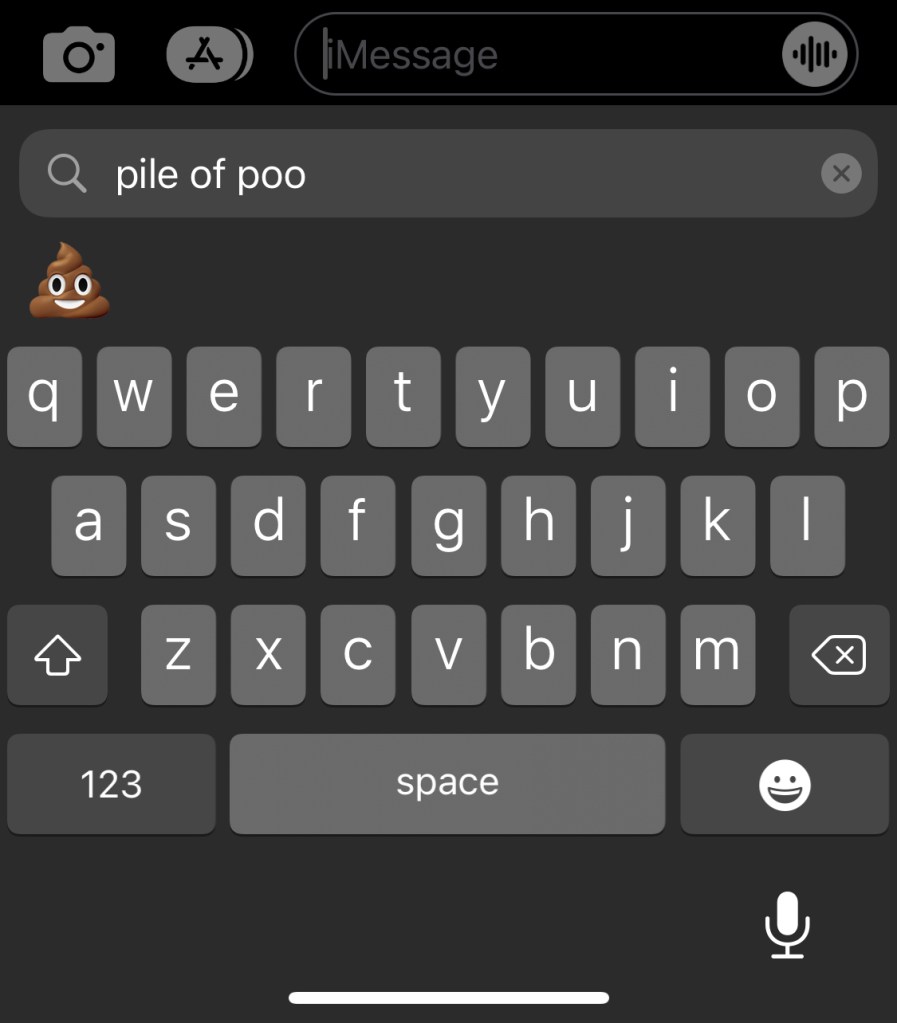
In the image above, you can see Apple’s tokenization of Unicode code point U+1F4A9, Unicode character name: “Pile of Poo.” If one were to want to send this Emoji to someone, they would click on the Emoji, creating a tokenization of it in the iMessage box, and then click send. Upon clicking send, four bytes—“11110000 : 10011111 : 10010010 : 10101001”—mapping to Unicode code point U+1F4A9 would be physically sent to the recipients device (let’s say, an Android phone). These bytes would then be decoded by the Unicode-aware text software layer in the Android phone and then matched to a new tokenization of the code point which would look like:

Which, is clearly not:

Or rather, it is. Both of the above graphic representations of Unicode Characters depict two tokenizations of the exact same type, that is, Unicode code point U+1F4A9, Unicode character name: “Pile of Poo.” The artistic liberties granted to the software developers and artists who create the layers of software that match decoded Unicode code points with proprietary pictographic representations adds a sense of fun to Emoji and help give devices their brand identity; but this practice is not without some small problems.
When is a Gun a Gun?
Unlike a languages’ abstract characters and glyphs, where every tokenization of each character and glyph tends to look more or less like what one would expect from each associated type—an A tends to always look like an A, no matter its flourishes due to the meaningful patterns of A—the variety of unique tokenizations of Emoji can conceivably lead to unfortunate bouts of miscommunication. For example:
In an article for the California Law Review titled: “#I 🔫 U: Considering the Context of Online Threats,” authors Lyrissa Barnett Lidsky and Linda Riedmann Norbut (2018) reflect on the difficulties of using Emojis as evidence of an intended meaning (1,908). Emojis, Lidsky and Norbut (2018) say, “are not consistent across platforms [they are platform-specific tokenizations]” (1,908). Look at the gun Emoji in the title of the article, Unicode code point U+1F52B, Unicode character name: “Pistol,” what does it look like? On some platforms, this Unicode code point is depicted as a squirt gun or water pistol:

The above image is a graphic representation of Apple’s current tokenization of Unicode code point U+1F52B, Unicode character name: “Pistol.” Apple released this tokenization of the pistol Emoji in 2016, prior to the switch, Apple’s tokenization of the pistol emoji looked like this:

While these two tokens look like completely separate characters, they are, in fact, re-tokenizations of the exact same type. By 2018, most platforms had switched their tokenization of Unicode code point U+1F52B, Unicode character name: “Pistol” from the classic pistol to the contemporary toy or “ray gun,” but not all of them. The LG Velvet mobile device, for instance, still tokenizes the Unicode code point as a gun:

Between 2016 and 2018, it would not be uncommon for an individual to send a squirt gun Emoji on one device, only to have it received as a handgun Emoji on another device. As stated earlier in this essay: That is because, when selecting an Emoji to share, the sender is not selecting a specific pictographic character… rather, they are selecting a Unicode code point, the type that they would like to have re-tokenized on the receiver’s device. Luckily, these rather drastic differences in tokenizations by platform are somewhat rare… but their occurrences are notable.
Emojis are tokens! are types! and that matters.
Emojis were created specifically with the intention to help disambiguate the emotional meaning of digital text (Morstatter et al. 2016, 1). It is, ironic then, that the increased presence and continued development of Emoji have led to additional, often stranger, kinds of ambiguity. Responding to a request for an encoded “Sliced Bagel” Emoji, Andrew West said, in a memo to the Unicode Technical Committee: “This character has always disturbed me. If it cannot be easily distinguished from a doughnut why are we encoding it? Even cutting in half does not help much because the b&w glyph at least just looks like two doughnuts.” And, if ambiguity exists amongst all the encoded Emojis in general, if the ambiguity exists at the type-level, it is only compounded by the differences in Emoji tokenizations across different platforms.
If Emoji is indeed, as WIRED’s Arielle Pardes (2018) states, “a primitive language… the first language born into the digital world,” Emoji deserve serious, rigorous study, and users should be encouraged to truly understand what they are doing when they are selecting an Emoji and what they are communicating when they send one. Emoji users particularly need to be aware that Emojis are platform-specific tokens tied to a universal, sendable-type; the look and feel of an Emoji token is entirely dependent on how the users’ prefered platform renders it. A Survey of 710 Twitter users found that at least 25% of respondents were unaware that Emoji they posted could appear differently to their followers (Miller Hillberg et al. 2018, 124:1). Miller Hillberg et al. (2018) additionally state that: “After being shown how one of their tweets rendered across platforms, 20% of respondents reported that they would have edited or not sent the tweet (124:1). In a separate study of Emoji (also on Twitter), Morstatter (2016) found that “8.627%, or, roughly 1 in every 11 [tweets studied] contain[ed] an Emoji used in a statistically different fashion on a different platform (8).
As Emoji continue to be encoded, ambiguities such as those discussed above are only bound to remain a problem. Still, according to the Unicode Consortium, Emoji encoding has been a boon for language support, they state: “Emoji draw on Unicode mechanisms that are used by various languages, but which had been incompletely implemented on many platforms. Because of the demand for emoji, many implementations have upgraded their Unicode support substantially. That means that implementations now have far better support for the languages that use the more complicated Unicode mechanisms.” So, while Emoji may be imperfect and ambiguous characters and glyphs not yet suitable as its own language (yet), the demand for Emoji have led to the implementation of better-Unicode compatibility and more opportunities for users to read and write in their own languages on their preferred devices.
Bibliography
Alonso, Daniel. 2021. “Emoji Timeline.” Emoji Timeline. 2021. https://emojitimeline.com/.
Irvine, Martin. 2020. “Introduction to Data Structures in Computing: Information, Data Types, and Design of a Semiotic Subsystem.” Google Docs. 2020.
———. 2022a. “Introducing Digital Electronic Information Theory: How We Design and Encode Electrical Signals as a Semiotic Subsystem.” Google Docs. 2022.
———. 2022b. “Introduction to Semiotics: A Unifying Model of Symbolic Thought, Symbolic Systems, and the Foundations of Computing.” Google Docs. 2022.
Lidsky, Lyrissa Barnett, and Linda Riedemann Norbut. 2018. “#I 🔫 U: Considering the Context of Online Threats.” California Law Review 106 (6): 1885–1930.
Miller Hillberg, Hannah, Zachary Levonian, Daniel Kluver, Loren Terveen, and Brent Hecht. 2018. “What I See Is What You Don’t Get: The Effects of (Not) Seeing Emoji Rendering Differences across Platforms.” Proceedings of the ACM on Human-Computer Interaction 2 (CSCW): 1–24.
Morstatter, Fred, Kai Shu, Suhang Wang, and Huan Liu. 2017. “Cross-Platform Emoji Interpretation: Analysis, a Solution, and Applications.” ArXiv:1709.04969 [Cs], September.
Nield, David. 2020. “Why Other People Can’t See Your Emojis and How to Fix It.” 2020. https://gizmodo.com/why-other-people-cant-see-your-emojis-and-how-to-fix-it-1820037259.
Oliveira, Natacha. 2021. “Emojis: Are They the Glyphs of the Twenty-First Century?” Melted.Design (blog). August 13, 2021. https://medium.com/melted-design/emojis-are-they-the-glyphs-of-the-twenty-first-century-1b5f78e1e83f
Pardes, Arielle. 2018. “The Complete History of Emoji.” Wired, 2018. https://www.wired.com/story/guide-emoji/.
Tasker, Peter. 2021. “How Unicode Works: What Every Developer Needs to Know About Strings and 🦄.” Delicious Brains. January 12, 2021. https://deliciousbrains.com/how-unicode-works/.
The Unicode Consortium. 2021. “Home.” Unicode. 2021. https://home.unicode.org/.
Zentgraf, David. 2015. “What Every Programmer Absolutely, Positively Needs to Know About Encodings and Character Sets to Work With Text.” 2015. https://kunststube.net/encoding/.
